
Unicode Standard
The Unicode Standard provides a unique number for each character, no matter the platform, program, or language. It is the universal character encoding standard used to represent text for computer processing.
Unicode provides a consistent way to encode multilingual plain text, making it easier to exchange text files internationally, as it defines codes for the characters of major languages. This includes punctuation marks, diacritics, mathematical and technical symbols, arrows, dingbats, etc.
In this section, GlobalVision describes best practices relating to the Unicode Standard.
Installing all necessary text encoding scripts on your computer
Risk
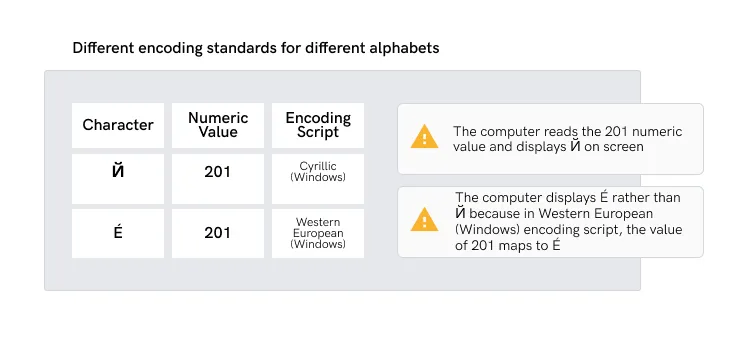
If you do not install all necessary text encoding scripts, text will appear as erroneous characters, garbled, or as Wingdings (question marks, boxes, stars, etc.: £®Ð£¸CPa ¡£Õ).
Issue
Alphabetic writing systems vary from one language to another. As a result,
computers need to utilize different encoding scripts. The character that is
displayed is dependent on the encoding script installed in your operating system.
NOTE: Some display languages/scripts are installed by default, while others require you to install additional language files.
Example
Solution
Do:
- Install all required encoding systems (scripts) on your computer.
- Identify the character encoding standards required for your work, such as UTF-8, UTF-16, or others.
- Install language packs or fonts to ensure proper rendering.
Don’t:
- Open files containing scripts that are not installed on your computer.
Tips
The following steps describe how to install or activate the necessary encoding
scripts (if applicable).
On Windows:
- Go to the Control Panel.
- Find the "Clock and Region" option and go to the "Administrative" tab.
- Click on the "Change system locale."
- Select the desired language and set it to the appropriate encoding (e.g., UTF-8).
On macOS:
- Open the "System Preferences."
- Go to Navigate to "Language & Region."
- Click on the "Advanced" button.
- Set the preferred language to the desired encoding (e.g., UTF-8).
Validating your fonts for all languages used
Risk
If you do not validate your fonts for all languages, screen-reader software for the blind and other programs will misinterpret the content or text in PDF files.
Issues
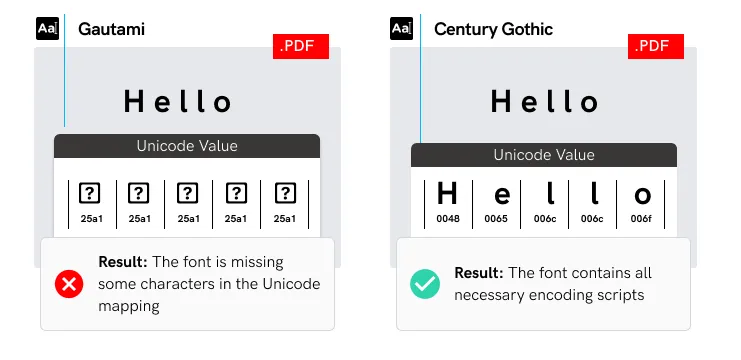
- Fonts are sold with different encoding script packages.
- The ability to type a specific font does not guarantee the font contains the
necessary encoding scripts for the language being used.
- Software programs cannot read characters if the font does not have all the
necessary encoding scripts (e.g. mg = £®).
Example
Solution
Do:
- Purchase the “Pro” version of a font.
- Check the supporting scripts when purchasing a font.
- Check the scripts that come with a font every time you switch languages and
fonts.
- Standardize on fonts used for each language.
- Check Glyph Coverage, use a character map or glyph viewer tool to explore the characters.
- Ensure that all characters and scripts render correctly
Don’t:
- Use fonts that support only a limited number of scripts.
- Use fonts without language testing.
Tips
The following steps detail how to validate a font with Apple Font Book:
- Open Font Book.
- Select the font in question from the font list.
- Click on File and select Validate Font.
- Check the validation results.
Using fonts that support Unicode
Risk
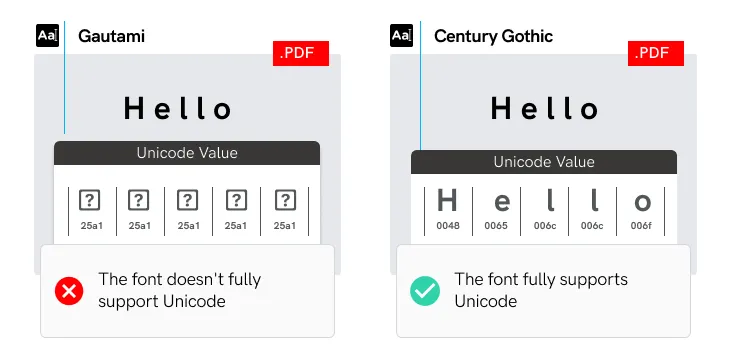
If you do not use fonts that support Unicode, character corruption may occur when transferring text to a PDF file.
Issue
Not all fonts support Unicode encoding.
Example
Solution
Do:
- Use fonts that are Unicode-based.
- Standardize on fonts throughout the PDF creation process.
- Use OpenType fonts. OpenType fonts support Unicode and offer advanced typographic features.
Don’t:
- Use bitmap (screen) fonts.
- Use legacy fonts that do not support Unicode.
Tips
The following steps detail how to identify Unicode characters.
In Microsoft Word:
- Select the character in question.
- Press ALT+X to display its Unicode value.
In Adobe Illustrator and InDesign:
- Go to the Type menu and select Glyphs.
- Click on the character in question to display its Unicode value.
Using the same list of Unicode Values for both Design and Word Files
Risk
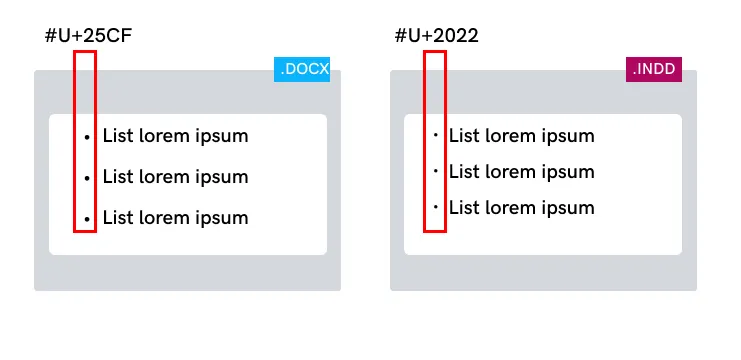
If you do not use the same list of Unicode values for both Design and Word files, inconsistencies may appear in different documents.
Issue
Duplicated text may be detected by the proofreading software.
Example
Solution
Do:
- Use the same equivalent Unicode value throughout your files.
- Use the same setup in Word vs. InDesign to maximize accuracy.
- Use a guideline for special characters.
- Convert bullets & numbers to text.
Don’t:
- Place PDF content in the text frame with extra text.
- Convert bullets to images.
Tips
The following steps describe how to view information about Unicode on Character Map (Windows) or Character Viewer (macOS). To explore and view information about Unicode characters:
On Windows:
- Find "Character Map" by searching in the Start menu.
On macOS:
- Access "Character Viewer" from the menu bar or by pressing "Control + Command + Space."
Ensuring the accuracy of text encoding from PDF
Risk
Incorrect encoding can lead to character misinterpretation and errors.
Issues
- The characters in PDF don't address Unicode character mapping, however, some character-encoding issues aren't repairable within Acrobat.
- The characters show correctly in PDF but when copying and pasting, gibberish characters are displayed.
Example

Solution
Do:
- Verify that the necessary fonts are installed on your system.
- Use a different font (preferably OpenType) in the original document and then re-create the PDF.
- Create PDF files in a newer version of Acrobat Producer.
- Consider the PDF version and use the latest versions available.
Don’t:
- Create PDFs with missing or uninstalled fonts in your system.
- Ignore PDF version compatibility.
Tips
Use the following accessibility checker to find problems that may prevent the document from being fully accessible.
- In Adobe Acrobat go to Tools> Accessibility > Accessibility Check > Click on Start Checking
- Read the accessibility report.
