
Norme Unicode
La norme Unicode fournit un numéro unique pour chaque caractère, quels que soient la plate-forme, le programme ou la langue. Il s'agit de la norme universelle de codage de caractères utilisée pour représenter le texte à des fins de traitement informatique.
Unicode fournit un moyen cohérent d'encoder du texte brut multilingue, ce qui facilite l'échange de fichiers texte au niveau international, car il définit des codes pour les caractères des principales langues. Cela inclut les signes de ponctuation, les signes diacritiques, les symboles mathématiques et techniques, les flèches, les dingbats, etc.
Dans cette section, GlobalVision décrit les meilleures pratiques relatives à la norme Unicode.
Installation de tous les scripts de codage de texte nécessaires sur votre ordinateur
Risque
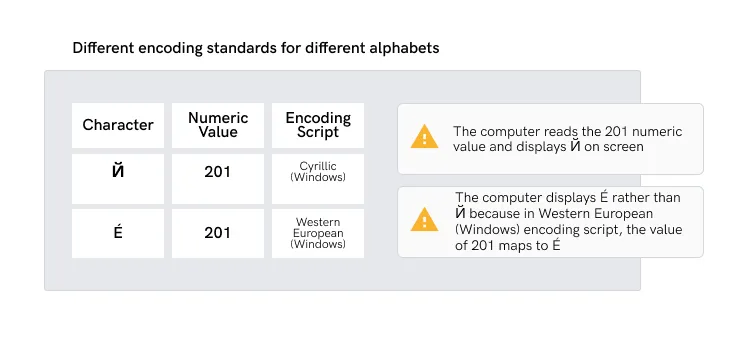
Si vous n'installez pas tous les scripts d'encodage de texte nécessaires, le texte apparaîtra sous forme de caractères erronés, déformés ou sous forme de Wingdings (points d'interrogation, cases, étoiles, etc. : £® ð£CPA ¡£○).
Problème
Les systèmes d'écriture alphabétique varient d'une langue à l'autre. En conséquence,
les ordinateurs doivent utiliser différents scripts de codage. Le personnage qui est
affiché dépend du script de codage installé sur votre système d'exploitation.
REMARQUE : Certaines langues/scripts d'affichage sont installés par défaut, tandis que d'autres nécessitent l'installation de fichiers de langue supplémentaires.
Exemple
Solution
Faire :
- Installez tous les systèmes de codage (scripts) requis sur votre ordinateur.
- Identifiez les normes de codage de caractères requises pour votre travail, telles que UTF-8, UTF-16 ou autres.
- Installez des modules linguistiques ou des polices pour garantir un rendu correct.
Ne pas :
- Ouvrez les fichiers contenant des scripts qui ne sont pas installés sur votre ordinateur.
Astuces
Les étapes suivantes décrivent comment installer ou activer le codage nécessaire
scripts (le cas échéant).
Sur Windows:
- Accédez au panneau de configuration.
- Recherchez l'option « Horloge et région » et accédez à l'onglet « Administratif ».
- Cliquez sur « Modifier les paramètres régionaux du système ».
- Sélectionnez la langue souhaitée et réglez-la sur le codage approprié (par exemple, UTF-8).
Sur macOS :
- Ouvrez les « Préférences système ».
- Accédez à « Langue et région ».
- Cliquez sur le bouton « Avancé ».
- Définissez la langue préférée selon le codage souhaité (par exemple, UTF-8).
Validation de vos polices pour toutes les langues utilisées
Risque
Si vous ne validez pas vos polices pour toutes les langues, les logiciels de lecture d'écran pour aveugles et d'autres programmes interpréteront mal le contenu ou le texte des fichiers PDF.
Enjeux
- Les polices sont vendues avec différents packages de script d'encodage.
- La possibilité de saisir une police spécifique ne garantit pas que la police contienne
les scripts d'encodage nécessaires pour la langue utilisée.
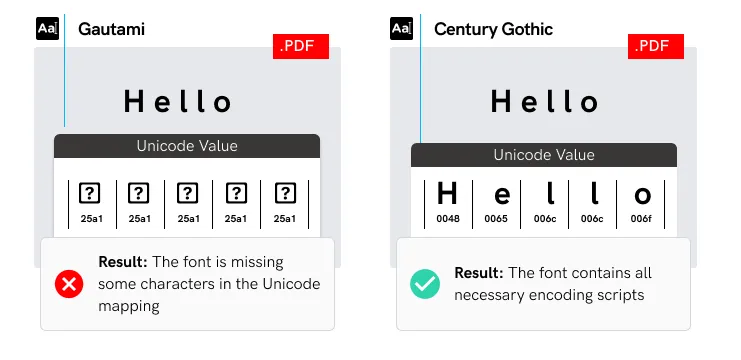
- Les logiciels ne peuvent pas lire les caractères si la police ne possède pas tous les
les scripts de codage nécessaires (par exemple mg = £®).
Exemple
Solution
Faire :
- Achetez la version « Pro » d'une police.
- Vérifiez les scripts correspondants lors de l'achat d'une police.
- Vérifiez les scripts fournis avec une police chaque fois que vous changez de langue et
polices de caractères.
- Standardisez les polices utilisées pour chaque langue.
- Vérifiez la couverture des glyphes, utilisez une carte de caractères ou un outil de visualisation de glyphes pour explorer les caractères.
- Assurez-vous que tous les caractères et scripts s'affichent correctement
Ne pas :
- Utilisez des polices qui ne prennent en charge qu'un nombre limité de scripts.
- Utilisez des polices sans test de langue.
Astuces
Les étapes suivantes expliquent comment valider une police avec Apple Font Book :
- Ouvrez Font Book.
- Sélectionnez la police en question dans la liste des polices.
- Cliquez sur Fichier et sélectionnez Valider la police.
- Vérifiez les résultats de validation.
Utilisation de polices compatibles Unicode
Risque
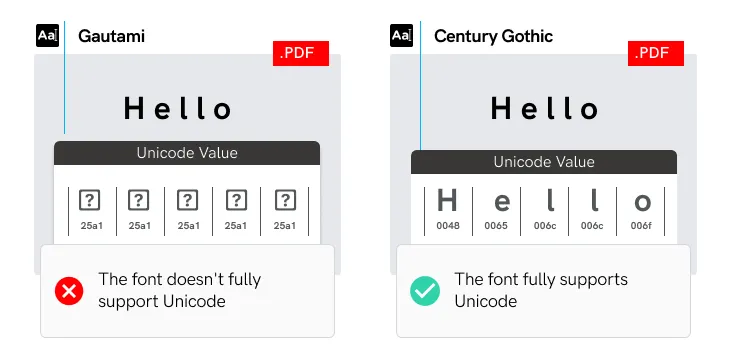
Si vous n'utilisez pas de polices compatibles Unicode, des caractères peuvent être corrompus lors du transfert de texte vers un fichier PDF.
Problème
Toutes les polices ne prennent pas en charge le codage Unicode.
Exemple
Solution
Faire :
- Utilisez des polices basées sur Unicode.
- Standardisez les polices tout au long du processus de création des PDF.
- Utilisez les polices OpenType. Les polices OpenType prennent en charge l'Unicode et offrent des fonctionnalités typographiques avancées.
Ne pas :
- Utilisez des polices bitmap (écran).
- Utilisez des polices héritées qui ne prennent pas en charge Unicode.
Astuces
Les étapes suivantes expliquent comment identifier les caractères Unicode.
Dans Microsoft Word :
- Sélectionnez le personnage en question.
- Appuyez sur ALT+X pour afficher sa valeur Unicode.
Dans Adobe Illustrator et InDesign :
- Accédez au menu Type et sélectionnez Glyphes.
- Cliquez sur le caractère en question pour afficher sa valeur Unicode.
Utilisation de la même liste de valeurs Unicode pour les fichiers de conception et les fichiers Word
Risque
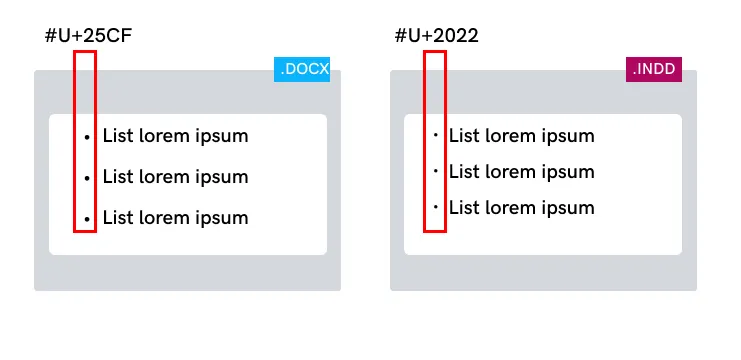
Si vous n'utilisez pas la même liste de valeurs Unicode pour les fichiers Design et Word, des incohérences peuvent apparaître dans différents documents.
Problème
Le texte dupliqué peut être détecté par le logiciel de relecture.
Exemple
Solution
Faire :
- Utilisez la même valeur Unicode équivalente dans tous vos fichiers.
- Utilisez la même configuration dans Word et InDesign pour optimiser la précision.
- Utilisez un guide pour les caractères spéciaux.
- Convertissez les puces et les chiffres en texte.
Ne pas :
- Placez le contenu du PDF dans la zone de texte contenant du texte supplémentaire.
- Convertissez les puces en images.
Astuces
Les étapes suivantes décrivent comment afficher les informations relatives à Unicode dans Character Map (Windows) ou Character Viewer (macOS). Pour explorer et consulter des informations sur les caractères Unicode, procédez comme suit :
Sur Windows :
- Trouvez « Character Map » en effectuant une recherche dans le menu Démarrer.
Sur MacOS:
- Accédez à « Character Viewer » depuis la barre de menu ou en appuyant sur « Control + Command + Space ».
Garantir la précision du codage du texte à partir d'un PDF
Risque
Un encodage incorrect peut entraîner une mauvaise interprétation des caractères et des erreurs.
Enjeux
- Les caractères du PDF ne résolvent pas le mappage des caractères Unicode, mais certains problèmes de codage des caractères ne sont pas réparables dans Acrobat.
- Les caractères s'affichent correctement dans le PDF, mais lors du copier-coller, des caractères de charabia s'affichent.
Exemple

Solution
Faire :
- Vérifiez que les polices nécessaires sont installées sur votre système.
- Utilisez une police différente (de préférence OpenType) dans le document d'origine, puis recréez le PDF.
- Créez des fichiers PDF dans une version plus récente d'Acrobat Producer.
- Pensez à la version PDF et utilisez les dernières versions disponibles.
Ne pas :
- Créez des PDF contenant des polices manquantes ou désinstallées dans votre système.
- Ignorez la compatibilité des versions PDF.
Astuces
Utilisez le vérificateur d'accessibilité suivant pour identifier les problèmes susceptibles d'empêcher l'accessibilité complète du document.
- Dans Adobe Acrobat, allez dans Outils > Accessibilité > Vérification de l'accessibilité > Cliquez sur Commencer la vérification
- Lisez le rapport sur l'accessibilité.
